
Appearance
HTTP 各版本差异 ✨
HTTP/1.0
无法复用连接
HTTP/1.0 为每个请求单独新开一个 TCP 连接
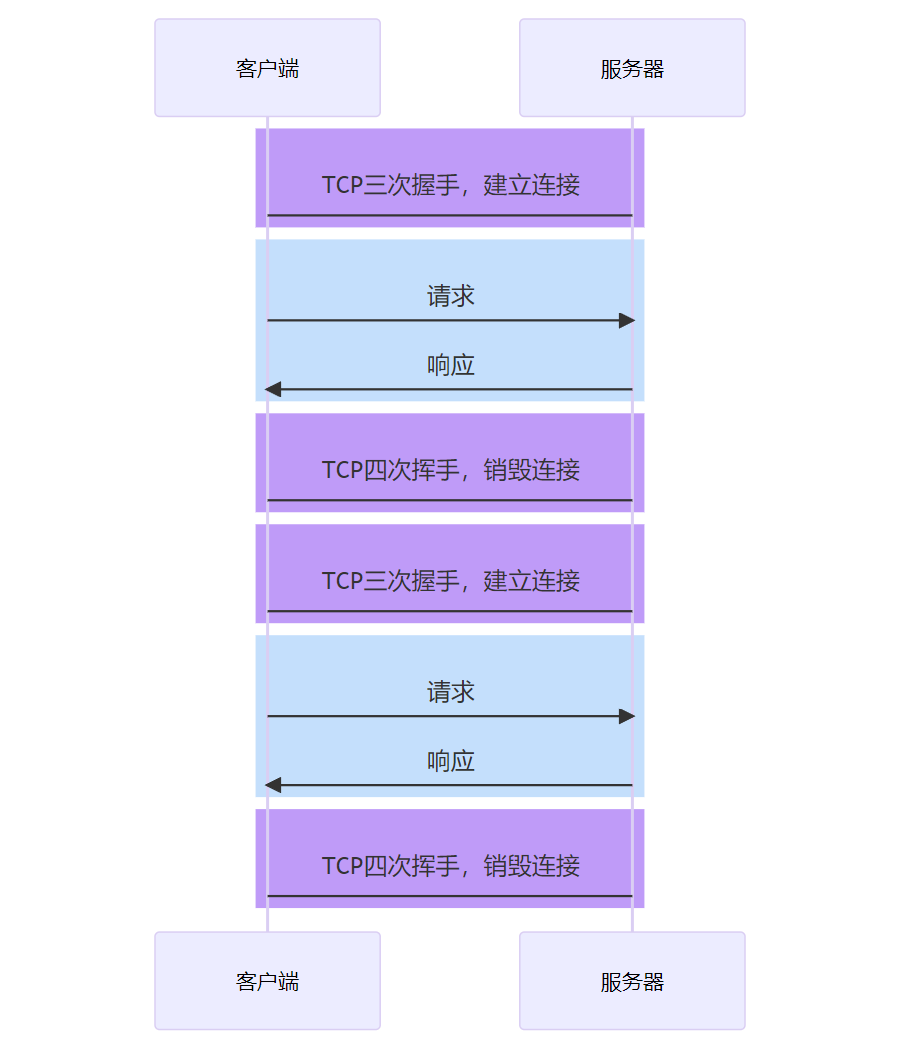
由于每个请求都是独立的连接,因此会带来下面的问题:
- 连接的建立和销毁都会占用服务器和客户端的资源,造成内存资源的浪费
- 连接的建立和销毁都会消耗时间,造成响应时间的浪费
- 无法充分利用带宽,造成带宽资源的浪费
TCP 慢启动
TCP 协议的特点是「慢启动」,即一开始传输的数据量少,一段时间之后达到传输的峰值。而上面这种做法,会导致大量的请求在 TCP 达到传输峰值前就被销毁了(拥塞控制)
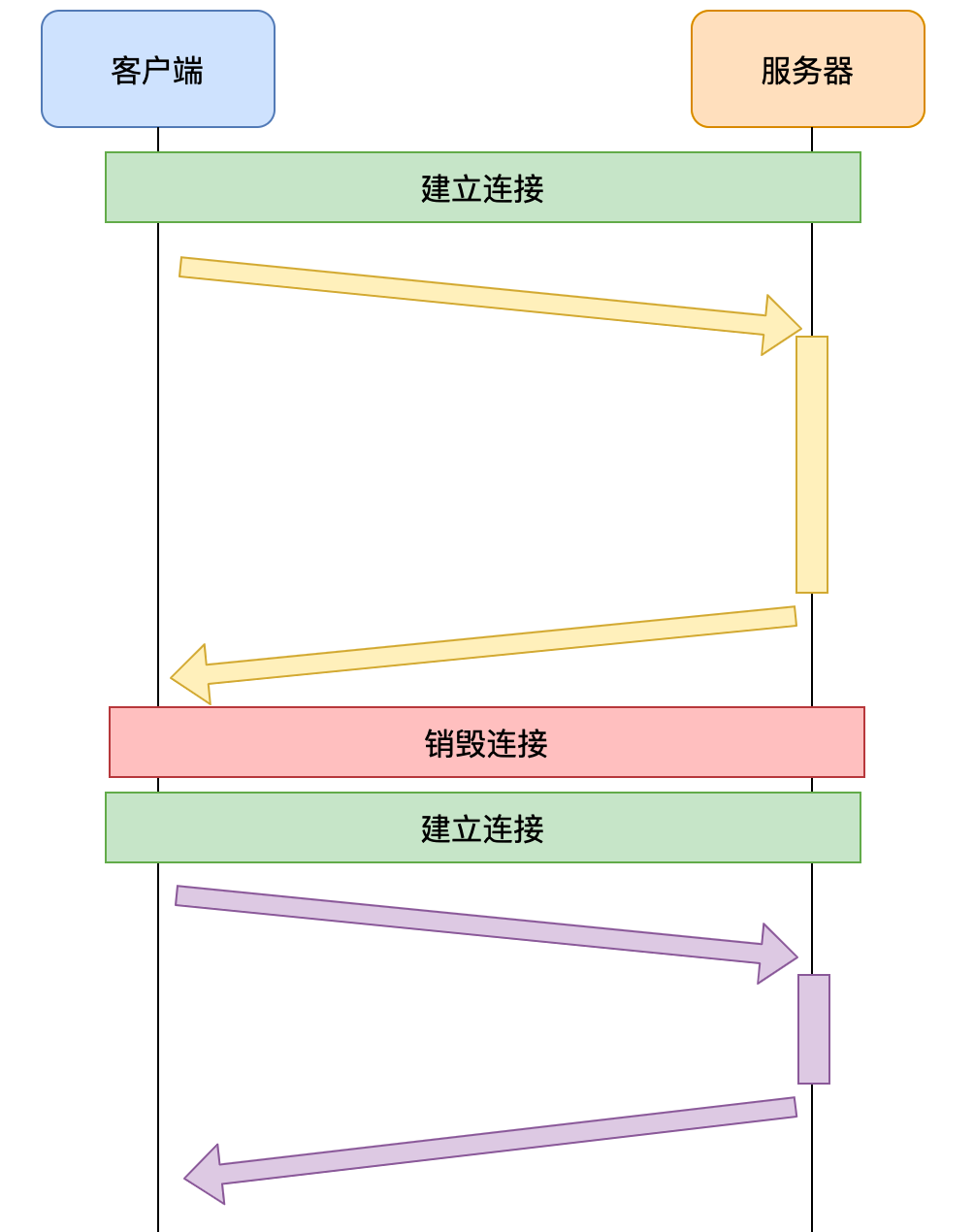
队头阻塞
HTTP/1.0 在一个 TCP 连接上一次只处理一个请求。客户端发送一个请求后,必须等待服务器返回完整的响应,才能发送下一个请求。这种串行机制意味着任何延迟都会直接影响后续请求。
HTTP/1.1
长连接(Keep-Alive)
为了解决 HTTP/1.0 的问题,HTTP/1.1 默认启用长连接,即让同一个 TCP 连接复用多次请求-响应。
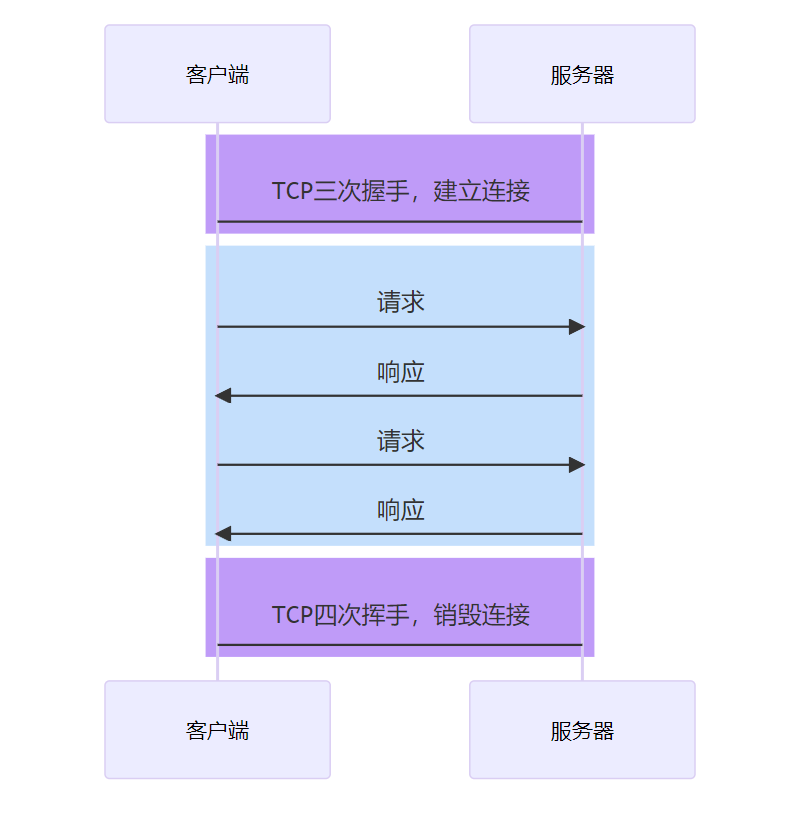
- 复用连接:减少握手/挥手次数,更好利用慢启动的带宽提升。
- 语义约定:
Connection: keep-alive表示希望复用连接;现代实现通常默认启用。 - 关闭时机:客户端或服务端可在需要时主动关闭,或在空闲超时后由服务端/代理清理。
http
GET /api/profile HTTP/1.1
Host: api.example.com
Connection: keep-alive
Accept: application/jsonjs
// Node.js (CommonJS)示例:通过 Agent 复用 HTTP/1.1 连接
const http = require("http");
const agent = new http.Agent({ keepAlive: true });
function get(path) {
return new Promise((resolve) => {
const req = http.request(
{ host: "api.example.com", path, agent },
(res) => {
let data = "";
res.on("data", (chunk) => (data += chunk));
res.on("end", () => resolve({ status: res.statusCode, data }));
}
);
req.end();
});
}
(async () => {
console.log(await get("/v1/profile"));
console.log(await get("/v1/notifications"));
})();常见误解
- Keep-Alive 并不等同于“应用层心跳”。TCP Keepalive(若开启)由操作系统维护,间隔与行为取决于系统配置,并非 HTTP 规范要求。
- 生产环境的连接清理通常由服务端/代理的“空闲超时”策略决定,而非客户端周期性心跳。
连接关闭的常见原因
- 一方显式发送
Connection: close,响应结束后关闭连接。 - 服务端/代理空闲超时到达,主动关闭长时间未活动的连接(可配置)。
- 网络异常或进程重启导致连接中断;操作系统的 TCP Keepalive 检测到对端不可达后关闭。
由于一个 TCP 连接可以承载多次请求响应,并在一段时间内保持可用,这种连接称为“长连接”。
管道化与队头阻塞
HTTP/1.1 的管道化允许在前一个响应未返回前继续发送后续请求;但响应必须严格按请求顺序返回,因此一旦有慢响应,后续响应将被阻塞,产生典型的队头阻塞(HOL)。

为什么响应必须按序返回?
- HTTP/1.1 的传输单元是完整的消息(状态行+头+体)。消息不可交错传输,缺少像 HTTP/2 那样的“流 ID”与分帧机制来在同一连接上区分与重组多条并行响应。
- 即便使用分块传输(Chunked),也只是“体”的分块,不同响应体仍不能交错;因此只能按请求顺序排队返回。
- 许多中间设备(代理、负载均衡)对乱序或交错响应不兼容,进一步强化“按序返回”的约束。
实际支持情况
- 现代浏览器普遍禁用 HTTP/1.1 管道化(兼容性与中间设备问题)。常见并发策略是“同域多连接”(通常上限约 6 条)。
常用优化
- 减少关键路径资源文件数量(打包/代码拆分/雪碧图/内联关键 CSS)。
- 利用多域名分发静态资源(同一个域名最多 6 个 TCP 连接),提升并发连接总数(有缺陷的并行)。
- 升级到 HTTP/2 或 HTTP/3,使用多路复用从根本上消除应用层队头阻塞。
HTTP/2.0

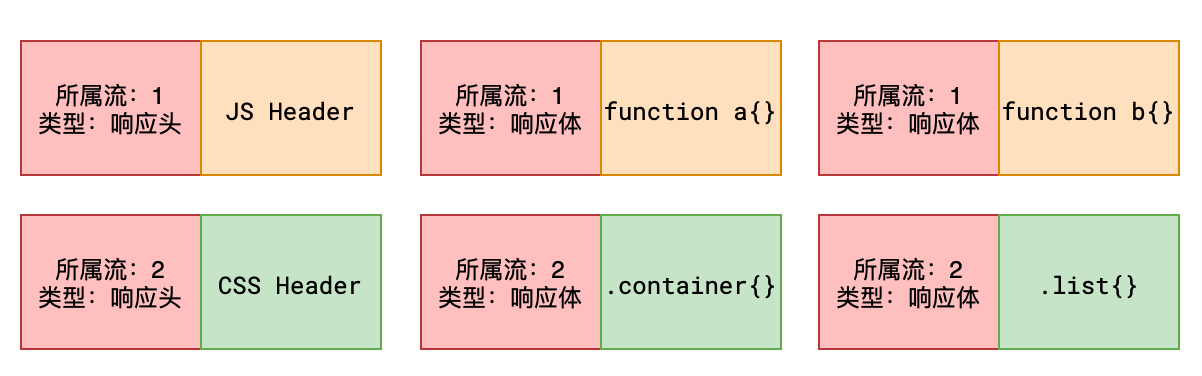
二进制分帧(Frames)与流(Streams)
核心直觉:把“整篇文档”切成可标记的小块(帧),并给每条请求/响应一个编号(流)。小块可以在同一 TCP 连接里交错传输,对端再按编号拼回去。
text
同一 TCP 连接上的交错传输(示意):
[HEADERS s=1][HEADERS s=3][DATA s=1][DATA s=3][DATA s=1]...- 帧(Frame):HTTP/2 的最小传输单位,常见类型有
HEADERS、DATA、SETTINGS等。 - 流(Stream):由多个帧组成的逻辑通道,每个流都有唯一
stream_id(请求与响应共用同一流)。 - 交错传输:不同流的帧可交错在同一连接传输,实现真正的并行与更高的带宽利用。
简单结论
- HTTP/1.x 传“整篇文档”,不能交错 → 容易队头阻塞。
- HTTP/2 传“带编号的小块”,可交错 → 同一连接并行,避免应用层队头阻塞。
更进一步(帧类型与优先级)
HEADERS帧承载伪头部(如:method/:path),配合 HPACK/QPACK 进行头部压缩。DATA帧承载实体内容(HTML/JS/CSS 等)。- 优先级:可为关键流设置更高优先级,但这是“建议值”,许多服务器/中间层可能忽略或自定策略。
深层限制
- HTTP/2 解决的是应用层的队头阻塞;它仍运行在 TCP 之上。链路丢包时,丢失的 TCP 包会阻塞该连接上的所有流(传输层 HOL)。要连传输层也消除,需要使用基于 QUIC/UDP 的 HTTP/3。
头部压缩(HPACK)
HTTP/2.0 之前,所有的消息头都是以字符的形式完整传输的
可实际上,大部分头部信息在多次请求中都有很多的重复
为了解决这一问题,HTTP/2.0 使用头部压缩来减少消息头的体积
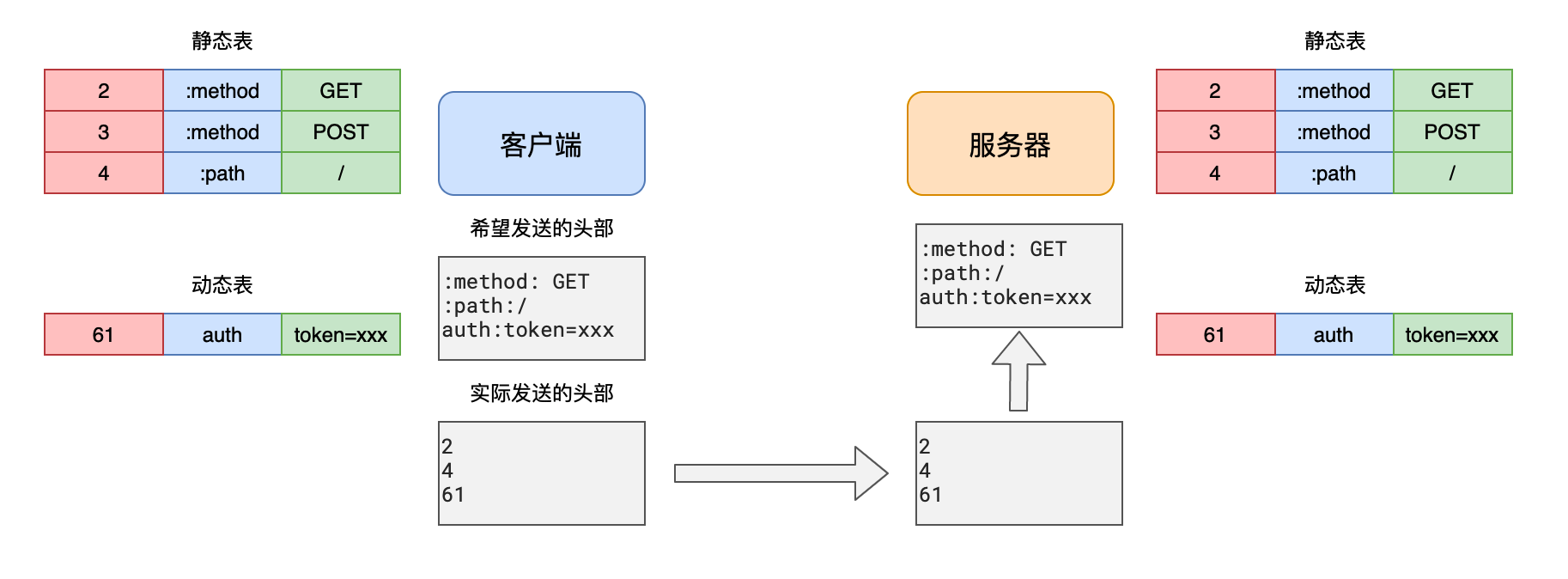
HPACK 直觉与机制
直觉:把常用头部做成“词典”(静态表+动态表),用索引代替长字符串;没见过的先添加再复用;仍需传输的字符串用霍夫曼编码压缩。
机制一览
- 静态表(Static Table):内置常见字段及典型值(如
:method: GET、:status: 200),可直接用索引发送。 - 动态表(Dynamic Table):会话内出现过的头部和值被记录并分配索引,后续复用时只发索引,避免重复字符串。
- 霍夫曼编码(Huffman):对仍需传输的字符串进行无损压缩,常见字符映射为更短的位序列。
- 差量更新:仅传递与上一请求相比发生变化的部分(如
cookie的新增片段)。
示例(概念演示):
text
请求 1 头部:
:method: GET
:path: /index.html
user-agent: curl/8.0
cookie: uid=123
→ 发送时:常见字段走静态表索引;首次出现的 user-agent/cookie 写入动态表。
请求 2 头部:
:method: GET
:path: /index.html
user-agent: curl/8.0
cookie: uid=123; theme=dark
→ 发送时:user-agent、cookie 基于动态表索引;仅对 cookie 的新增部分按差量+霍夫曼传输。注意
- 动态表大小有限(典型约 4KB,可配置),过大的
cookie可能被截断或频繁驱逐,收益有限。 - HPACK 的动态表是“按方向维护”的(客户端 → 服务器、服务器 → 客户端各自独立)。
- HTTP/3 使用 QPACK(为解决 QUIC 下乱序问题),与 HPACK 存在实现差异。
HTTP/2 请求行与伪头部
HTTP/1.x 的文本请求行(如 GET /index.html HTTP/1.1)在 HTTP/2 中被“伪头部”字段替代,并承载在 HEADERS 帧中:
text
:method: GET
:path: /index.html
:scheme: https
:authority: example.com- 这些以冒号开头的字段仅在 HTTP/2 使用,替代请求行与部分头部。
- 规则:伪头部必须位于普通头部之前,且不允许重复或与普通头部混淆(如
host与:authority的关系)。
js
// Node.js(CommonJS)示例:用伪头部发起 HTTP/2 请求
const http2 = require("http2");
const client = http2.connect("https://example.com");
const req = client.request({ ":method": "GET", ":path": "/" });
req.on("response", (headers) => {
// 读取响应头
});
req.on("data", (chunk) => process.stdout.write(chunk));
req.on("end", () => client.close());
req.end();简明结论
- HTTP/2 使用二进制帧与伪头部替代文本请求行;配合 HPACK 可显著减少重复头部开销。
服务器推
HTTP/2.0 允许在客户端没有主动请求的情况下,服务器预先把资源推送给客户端
当客户端后续需要请求该资源时,则自动从之前推送的资源中寻找
面试题精选
1. 简述 HTTP/1.0、HTTP/1.1、HTTP/2 的核心区别
一句话总结
- 1.0:短连接、串行请求、队头阻塞严重。
- 1.1:默认长连接与管道化(多被禁用),应用层 HOL 仍在。
- 2:分帧与多路复用、头部压缩,显著提升并发与带宽利用。
- HTTP/1.0:每次请求独立连接(握手/挥手开销大),响应完成后才能发下一个请求。
- HTTP/1.1:启用
Connection: keep-alive复用连接,管道化允许连续发请求但响应必须按序返回。 - HTTP/2:将消息拆成带“流 ID”的二进制帧,在同一连接交错传输;配合 HPACK 压缩头部。
2. 为什么 HTTP/1.1 不能真正多路复用?
- 消息不可交错:传输单元是完整响应文本,缺少流 ID 与分帧机制,响应必须按请求顺序返回。
- 慢响应会阻塞队列:后续响应不能越序返回,形成应用层队头阻塞(HOL)。
3. 用简洁语言说明 HTTP/2 的多路复用
- 把“整篇文档”切成标记了流 ID 的小帧,小帧在同一连接交错传输;对端按编号组装回各自的流。
- 同一连接即可并行多个请求与响应,避免 HTTP/1.x 的应用层队头阻塞。
4. HTTP/1.1 如何复用 TCP 连接?
- 通过请求头
Connection: keep-alive表示希望复用连接;现代实现默认启用。 - 空闲超时后由服务端/代理关闭;需要断开时可显式
Connection: close。
http
GET /api/profile HTTP/1.1
Host: api.example.com
Connection: keep-alive
Accept: application/json5. 概览:HTTP/1.0、HTTP/2、HTTP/3 的关键差异
- 连接与并发:
- 1.0:短连接,串行。
- 2:单连接多路复用(应用层 HOL 消除)。
- 3:QUIC/UDP,连传输层 HOL 一并解决,支持 0-RTT 与连接迁移。
- 头部压缩:
- 1.x:无。
- 2:HPACK。
- 3:QPACK(适配 QUIC 的乱序特性)。
- 推送能力:
- 2:曾支持 Server Push(现多不推荐)。
- 部署要点:
- 2:需启用 TLS 与 ALPN;优先级为建议值,部分服务可能忽略。
- 3:需支持 QUIC/UDP 与防火墙策略,建议与 2 并行灰度启用。
真实世界注意
- 管道化在浏览器端基本禁用;多连接并发只是权宜之计。
- HTTP/2 多路复用提升显著,但在丢包严重的网络下仍会受 TCP 传输层队头阻塞影响;此时启用 HTTP/3 更优。